|
Nov 2019 - Dec 2019
|
Columbia University
|
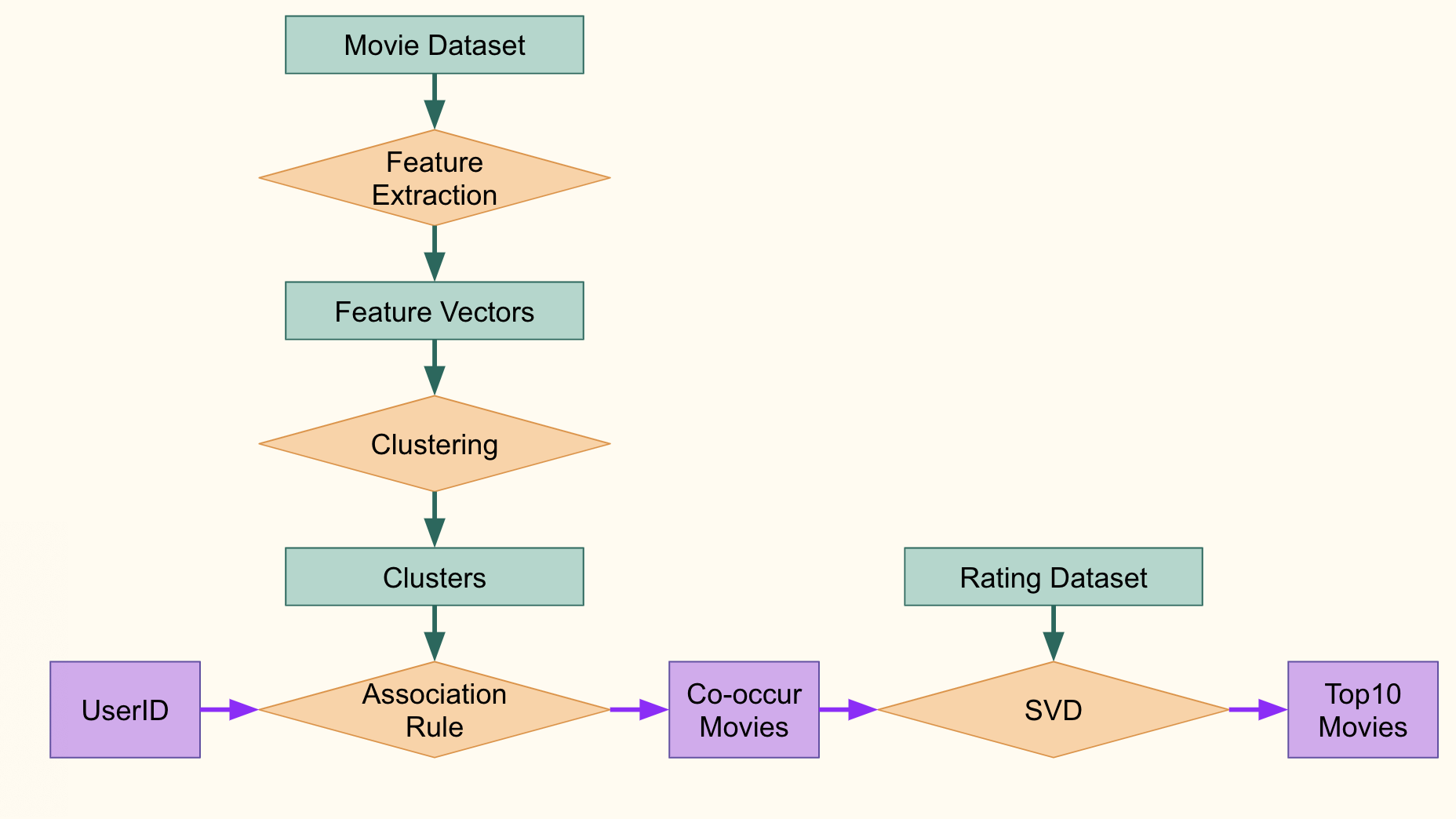
Movie Recommendation System
|
Collected movie information and user rating data from IMDB, TMDB and GroupLens, and loaded them into Google BigQuery using SQL. Ran exploratory data analysis by R, gave insight into the data. Performed ssociation rule and Single Value Decomposition methods by PySpark, give out personalized recommended movies. - Used HTML, Django and SVG to build a graphical user interface system, and deployed it on Google App Engine.
|
|
Nov 2019 - Dec 2019
|
Columbia University
|
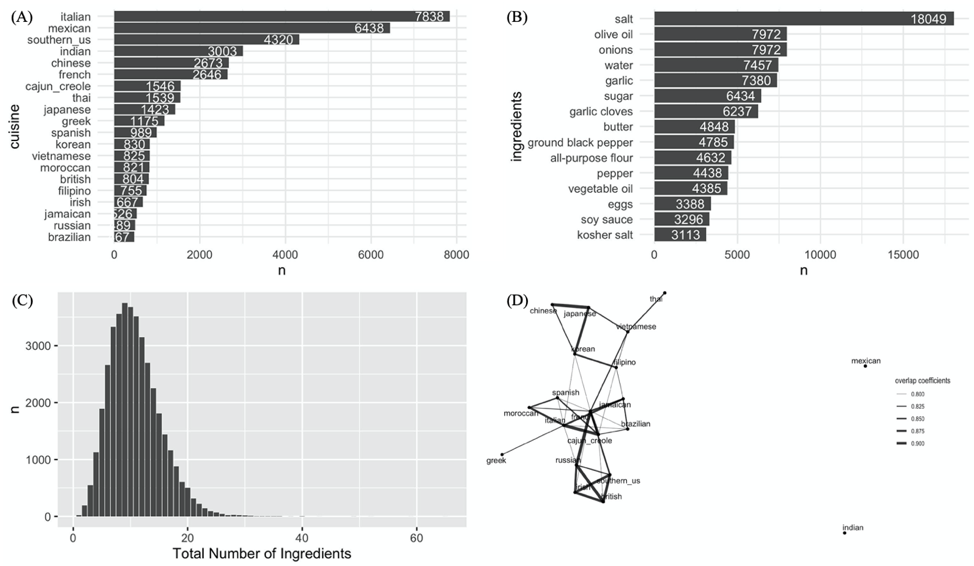
Cooking Recipe Cuisine Type Prediction
|
Collected cooking recipe data from Kaggle and performed exploratory data analysis by R, reveal the difference between each cuisine type. Used ‘Tokenizer’ to break list ingredients into individual words, then compared two feature extraction methods ‘Word2Vec’ and ‘TF-IDF’, found out ‘TF-IDF’ is better in capturing the hidden feature. - Compared four machine learning methods SVM, logistic regression, decision tree and random forest by using
Pyspark, and found out logistic regression gives the highest prediction accuracy.
|
|
Oct 2019 - Oct 2019
|
Columbia University
|
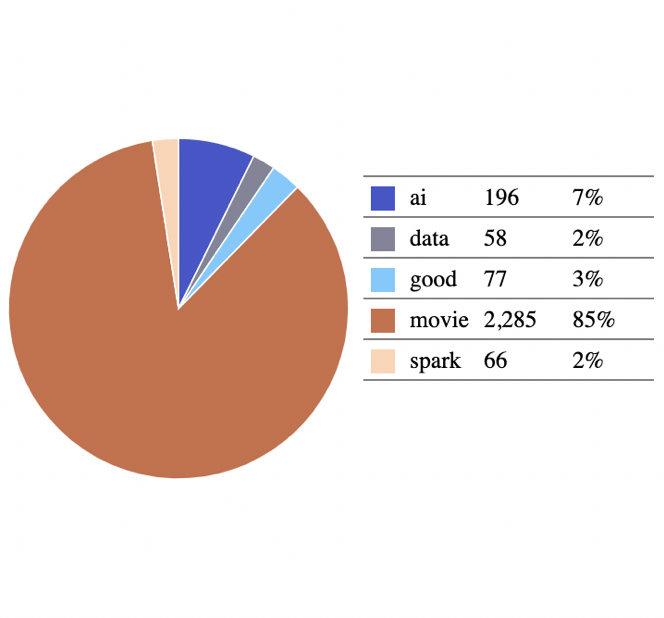
Twitter Steaming Data Analysis
|
|
|
|
Mar 2019 - Apr 2019
|
Columbia University
|
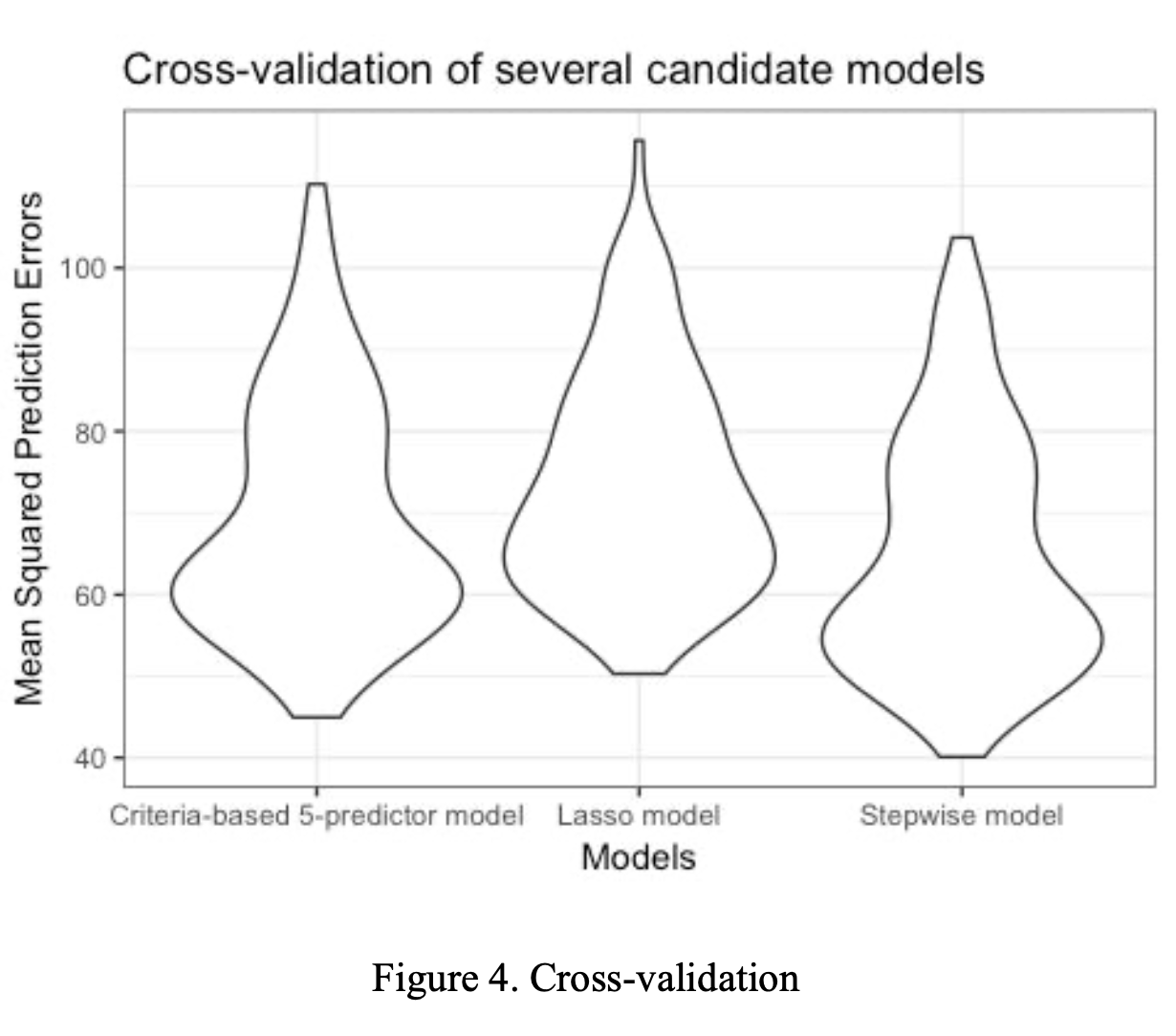
Predictive Model For Down Syndrome Disease
|
Used R to build a predictive model based on logistic regression to facilicate down syndrome diagnosis. Compared methods including and Pathwise Coordinate Descent with regularized logistic regression and smoothed bootstrap estimation, found out that Smoothed Bootstrap Estimation provides a more accurate classification result. - Identified a subset of proteins that are significantly associated with Down syndrome using the best method.
|
|
Dec 2018 - Dec 2018
|
Columbia University
|
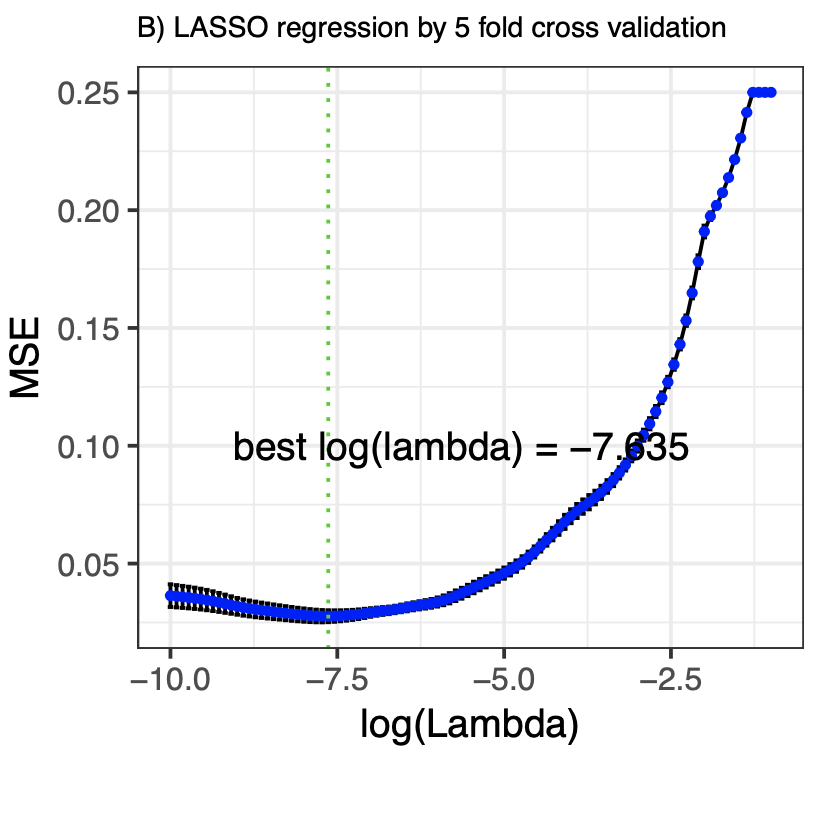
Model Selection For Better Cancer Diagnose
|
- Collected the cancer statistics dataset containing information from cancer.gov, census.gov and clinicaltrials.gov, performed different model selection strategies like forward selection, backward selection and LASSO with cross validation in R, selected a set of predictors that ‘best’ predicts cancer mortality.
|

|
Nov 2018 - Dec 2018
|
Columbia University
|
Data Science Job Marketing Analysis
|
Launched exploration from a general trend finding through data from National Occupational Employment Status and Wage Estimates from the US Bureau of Labour Statistics. Found out most required skills and background majors for data-related jobs, and the difference in qualification between Fortune 500 and non-Fortune 500 companies. - Used
shiny and flexdashboard R package to create Dashboard and multiple visualization tools to represent our findings.
|
|
Oct 2018 - Oct 2018
|
Columbia University
|
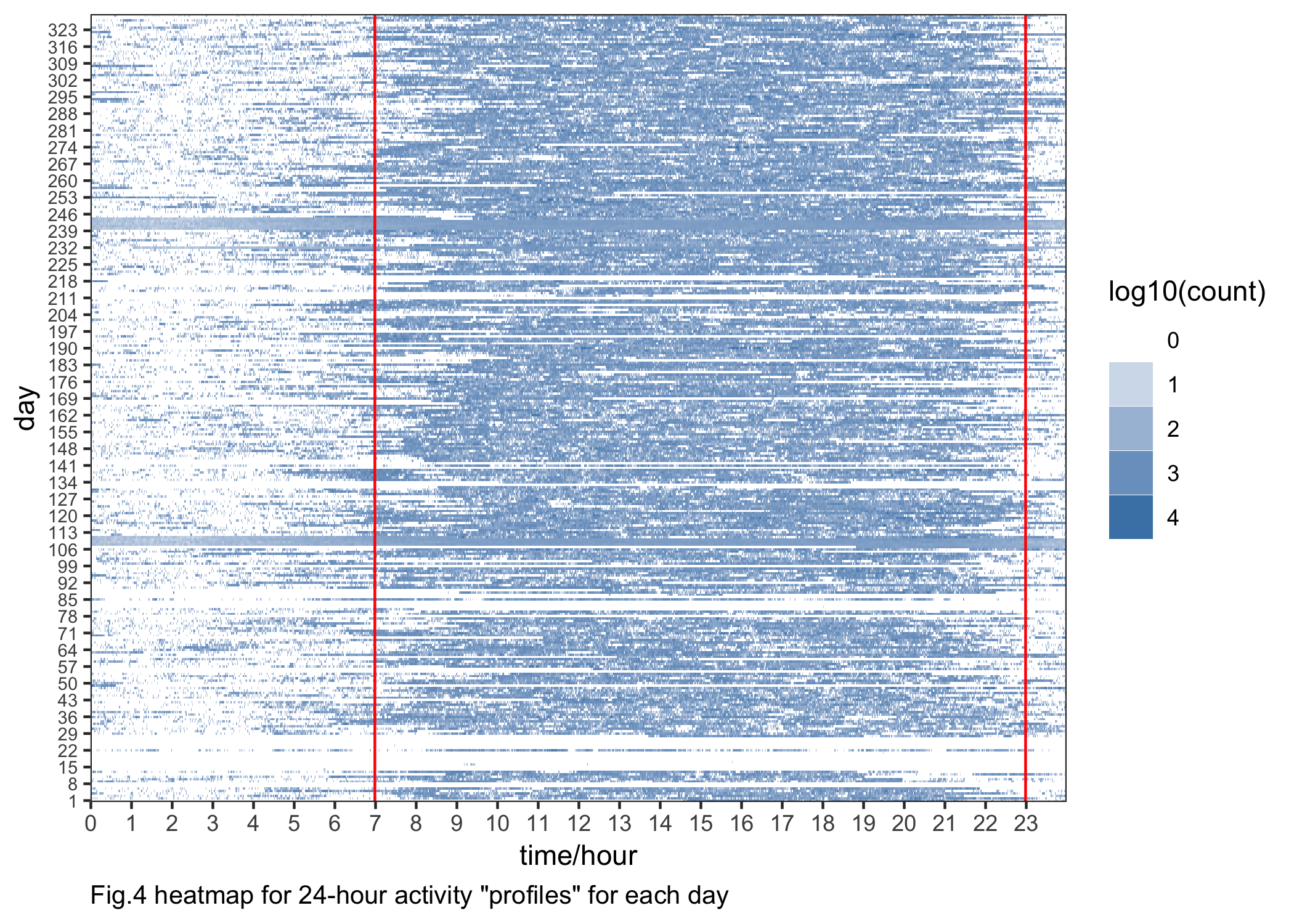
Congestive Heart Failure Profile Analysis
|
|
|
|
Dec 2015 - May 2017
|
Shanghai Jiao Tong University
|
Assessment of Zero-Inflated Model
|
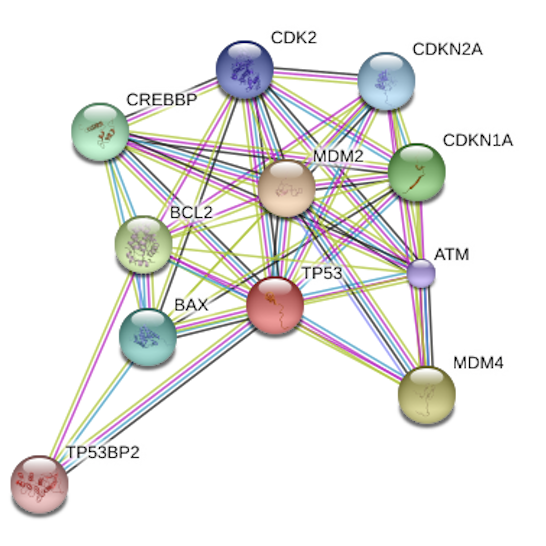
Proposed a biological network module-based zero-augmented generalized linear model for differential expression analysis. Conducted two simulation studies by using parallel computing on cluster to compare the efficacy between zero-inflated model, hurdle model and negative binomial model, found out zero-inflated Poisson model gave out best performance. - Applied models to CPTAC colorectal cancer data set, and identified subtler protein pathways and modules that can not been detected by normal model.
|